-
Mitogen, an infrastructure code baseline that sucks less

After many years of occasional commitment, I'm finally getting close to a solid implementation of a module I've been wishing existed for over a decade: given a remote machine and an SSH connection, just magically make Python code run on that machine, with no hacks involving error-prone shell snippets, temporary files, or hugely restrictive single use request-response shell pipelines, and suchlike.
I'm borrowing some biology terminology and calling it Mitogen, as that's pretty much what the library does. Apply some to your program, and it magically becomes able to recursively split into self-replicating parts, with bidirectional communication and message routing between all the pieces, without any external assistance beyond an SSH client and/or sudo installation.
Mitogen's goal is straightforward: make it childsplay to run Python code on remote machines, eventually regardless of connection method, without being forced to leave the rich and error-resistant joy that is a pure-Python environment. My target users would be applications like Ansible, Salt, Fabric and similar who (through no fault of their own) are universally forced to resort to obscene hacks in their implementations to affect a similar result. Mitogen may also be of interest to would-be authors of pure Python Internet worms, although support for autonomous child contexts is currently (and intentionally) absent.
Because I want this tool to be useful to infrastructure folk, Mitogen does not require free disk space on the remote machines, or even a writeable filesystem -- everything is done entirely in RAM, making it possible to run your infrastructure code against a damaged machine, for example to implement a repair process. Newly spawned Python interpreters have import hooks and logging handlers configured so that everything is fetched or forwarded over the network, and the only disk accesses necessary are those required to start a remote interpreter.
Recursion
Mitogen can be used recursively: newly started child contexts can in turn be used to run portions of itself to start children-of-children, with message routing between all contexts handled automatically. Recursion is used to allow first SSHing to a machine before sudoing to a new account, all with the user's Python code retaining full control of each new context, and executing code in them transparently, as easily as if no SSH or sudo connection were involved at all. The master context is able to control and manipulate children created in this way as easily as if they were directly connected, the API remains the same.
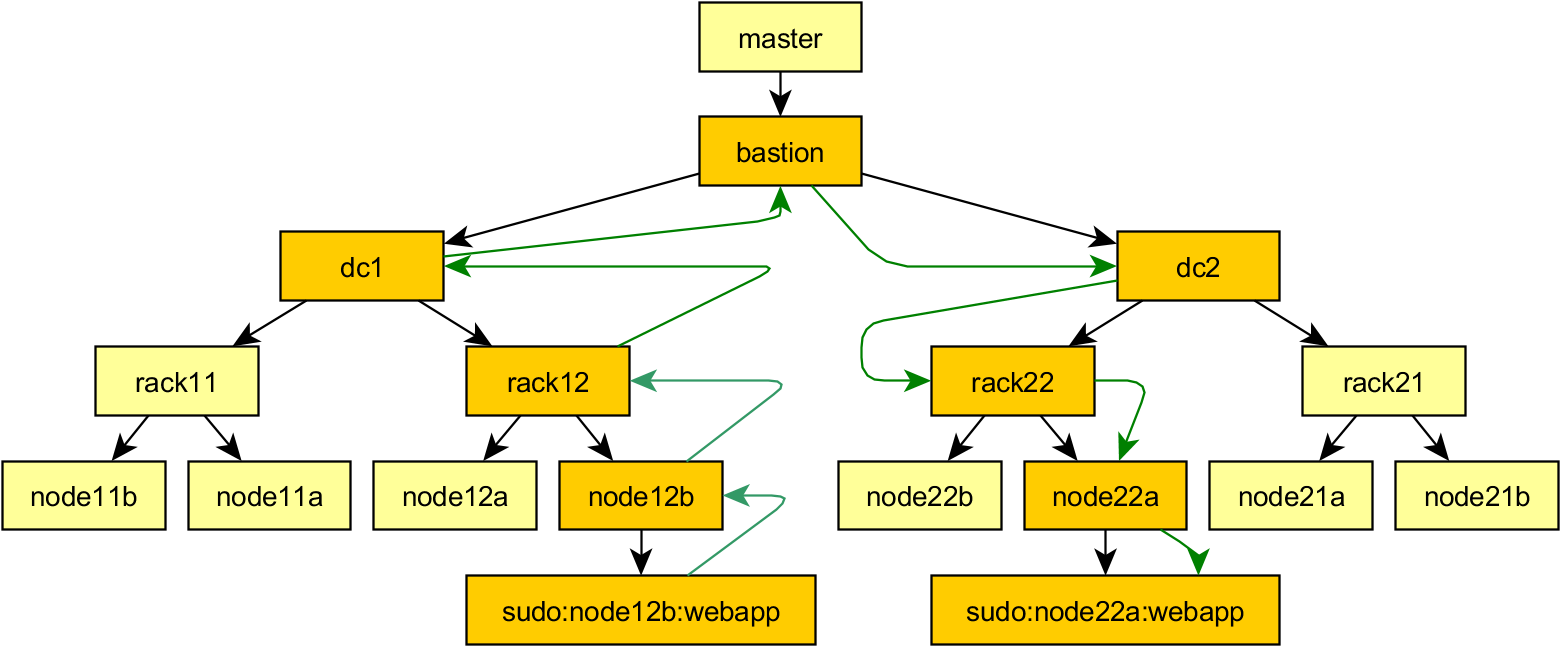
Currently there exists just two connection methods: ssh and sudo, with the sudo support able to cope with typing passwords interactively, and crap configurations that have
requirettyenabled.I am explicitly planning to support Windows, either via WMI, psexec, or Powershell Remoting. As for other more exotic connection methods, I might eventually implement bootstrap over an IPMI serial console connection if for nothing else then as a demonstrator of how far this approach can be taken, but the ability to use the same code to manage a machine with or without a functional networking configuration would be in itself a very powerful feature.
This looks a bit like X. Isn't this just X?
Mitogen is far from the first Python library to support remote bootstrapping, but it may be the first to specifically target infrastructure code, minimal networking footprint, read-only filesystems, stdio and logging redirection, cross-child communication, and recursive operation. Notable similar packages include Pyro and py.execnet.
This looks a bit like Fabric. Isn't this just Fabric?
Fabric's API feels kinda similar to what Mitogen offers, but it fundamentally operates in terms of chunks of shell snippets to implement all its functionality. You can't easily (at least, as far as I know) trick Fabric into running your Python code remotely, or for that matter recursively across subsequent sudo and SSH connections, and arrange for that code to communicate bidirectionally with code running in the local process and autonomously between any spawned children.
Mitogen internally reuses this support for bidirectional communication to implement some pretty exciting functionality:
SSH Client Emulation
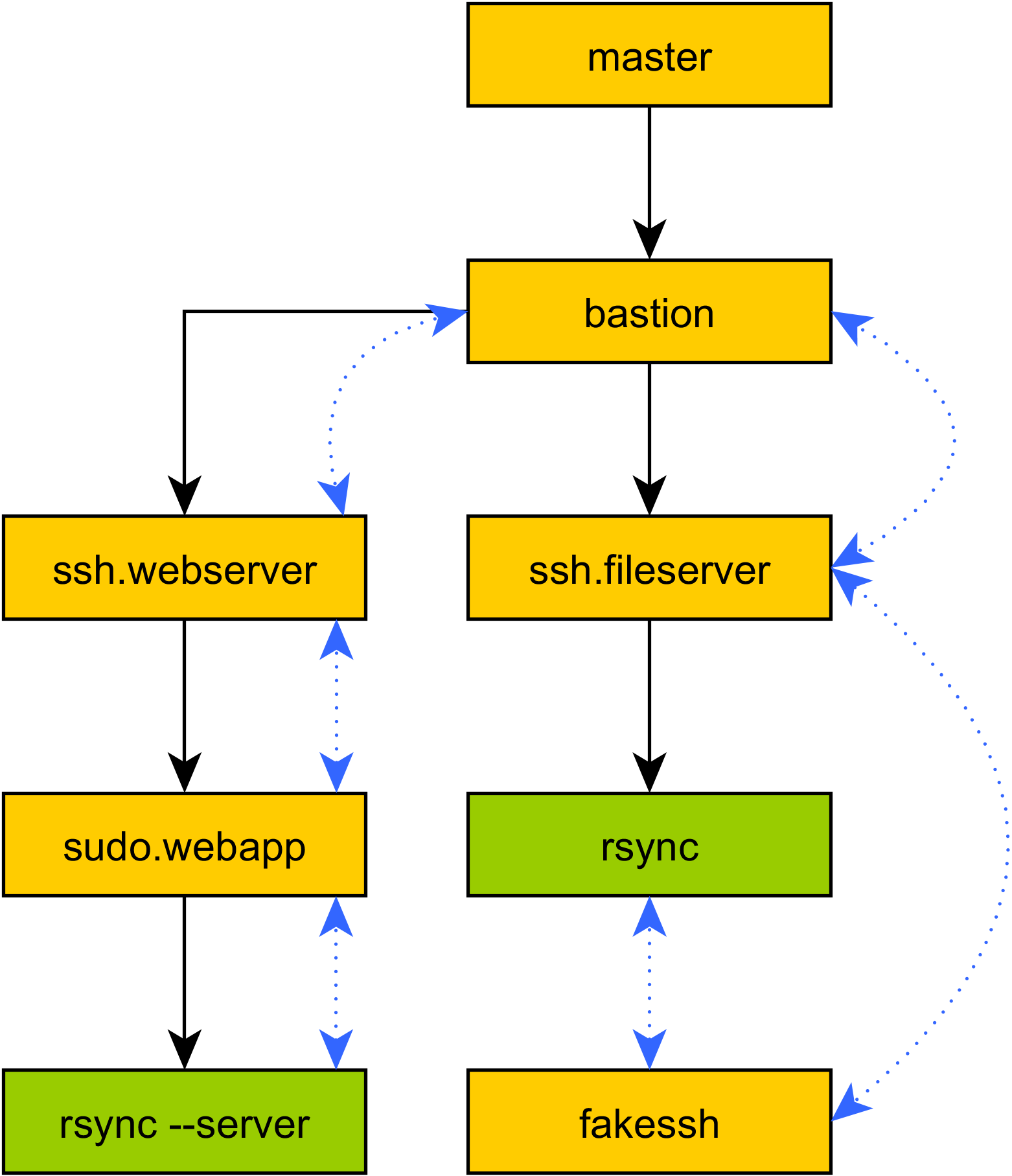 So your program has an elaborate series of tunnels setup, and it's running code all over the place. You hit a problem, and suddenly feel the temptation to drop back to raw shell and SSH again: "I just need to sync some files!", you tell yourself, before loudly groaning on realizing the spaghetti of duplicated tunnel configurations that would be required to get
So your program has an elaborate series of tunnels setup, and it's running code all over the place. You hit a problem, and suddenly feel the temptation to drop back to raw shell and SSH again: "I just need to sync some files!", you tell yourself, before loudly groaning on realizing the spaghetti of duplicated tunnel configurations that would be required to get rsyncrunning the same way as your program. What's more, you realize that you can't even usersync, because you're relying on Mitogen's ability to run code oversudowithrequirettyenabled, and you can't even directly log into that target account.Not a problem: Mitogen supports running local commands with a modified environment that causes their attempt to use SSH to run remote command lines to be redirected into Mitogen, and tunnelled over your program's existing tunnels. No duplicate configuration, no wasted SSH connections, no 3-way handshake latency.
The primary goal of the SSH emulator to simplify porting existing infrastructure scripts away from shell, including those already written in Python. As a first concrete target for Mitogen, I aim to retrofit it to Ansible as a connection plug-in, where this functionality becomes necessary to support e.g. Ansible's
synchronizemodule.Compared To Ansible
To understand the value of Mitogen, a short comparison against Ansible may be useful. I created an Ansible playbook talking to a VMWare Fusion Ubuntu machine, with SSH pipelining enabled (the current best performance mode in Ansible). The playbook simply executes
/bin/truewithbecome: trueand discards the result 100 times.I then created an equivalent script written against Mitogen, using its SSH and sudo functionality, and finally a trivial change to the Mitogen variant that executes the control loop on the target machine. In terms of architecture, the first Mitogen script is closer to a fair comparison to Ansible's control flow, but the latter is a good example of the kind of intelligence Mitogen enables that would be messy, if not close to impossible with Ansible's existing architecture.
[Side note: this is comparing performance characteristics only, in particular I am not advocating writing code against Mitogen directly! It's possible, but you get none of the ease of use that a tool like Ansible provides. On saying that, though, a Mitogen-enabled tool composed of tens of modules would have similar performance to the numbers below, just a slightly increased base cost due to initial module upload]
Method Bytes A→B Bytes B→A Packets A→B Packets B→A Duration (ms) Ansible default 5,001,352 486,500 8,864 4,460 55,065 Ansible pipelining 4,562,905 178,622 4,282 2,033 25,643 Mitogen local loop 45,847 17,982 247 135 1,245 Mitogen remote loop 22,511 5,766 51 39 784 The first and most obvious property of Ansible is that it uses a metric crap-ton of bandwidth, averaging 45kb of data for each run of /bin/true. In comparison, the raw command line "
ssh host /bin/true" generates only 4.7kb and 311ms, including SSH connection setup and teardown.Bandwidth aside, CPU alone cannot account for runtime duration, clearly significant roundtrips are involved, generating sufficient latency to become visible on an in-memory connection to a local VM. Why is that? Things are about to get real ugly, and I'm already starting to feel myself getting depressed. Remember those obscene hacks I mentioned earlier? Well, buckle your seatbelt Dorothy, because Kansas is going bye-bye..
The Ugly
[Side note: the name Ansible is borrowed from Ender's Game, where it refers to a faster-than-light communication technology. Giggles]
 When you write some code in Ansible, like
When you write some code in Ansible, like shell: /bin/true, you are telling Ansible (in most cases) that you want to execute a module namedshell.pyon the target machine, passing/bin/trueas its argument.So far, so logical. But how is Ansible actually running
shell.py? "Simple", by default (no pipelining) it looks like this:- First it scans
shell.pyfor every module dependency, - then it adds the module and all dependents into an in-memory ZIP file, alongside a file containing the module's serialized arguments,
- then it base64-encodes this ZIP file and mixes it into a templatized self-extracting Python script (
module_common.py), - then it writes the templatized script to the local filesystem, where it can be accessed by
sftp, - then it uploads the script to the target machine:
- first it runs a fairly simple bash snippet over SSH to find the user's home directory,
- then it runs a bigger bash snippet to create a temporary directory in the user's home directory in which to write the templatized script,
- then it starts an sftp session and uses it to write the templatized script to the new temporary directory,
- then it runs another snippet over SSH to mark the script executable,
- then it wraps a snippet to execute the templatized script using an obscene layer of quoting (16 quotes!!!) and passes it to sudo,
- finally the templatized script runs:
- first it creates yet another temporary directory on the target machine, this time using the
tempfilemodule, - then it writes a base64-decoded copy of the embedded ZIP file as
ansible_modlib.zipinto that directory, - then it opens the newly written ZIP file using the
zipfilemodule and extracts the module to be executed into the same temporary directory, named likeansible_mod_<modname>.py, - then it opens the newly written ZIP file in append mode and writes a custom
sitecustomize.pymodule into it, causing the ZIP file to be written to disk for a second time on this machine, and a third time in total, - then it uses the
subprocessmodule to execute the extracted script, withPYTHONPATHset to cause Python's ZIP importer to search for additional dependent modules inside the extracted-and-modified ZIP file, - then it uses the
shutilmodule to delete the second temporary directory,
- first it creates yet another temporary directory on the target machine, this time using the
- then the shell snippet that executed the templatized script is used to run
rm -rfover the first temporary directory.
When pipelining is disabled, which is the default, and required for cases where
sudohasrequirettyenabled, these steps (and their associated network roundtrips) recur for every single playbook step. And now you know why Ansible makes execution over a local 1Gbit LAN feel like it's communicating with a host on Mars.Need a breath? Don't worry, things are about to get better. Here are some pretty graphs to look at while you're recovering..
The Ugly (from your network's perspective)
This shows Ansible's pipelining mode, constantly reuploading the same huge data part and awaiting a response for each run. Be sure to note the sequence numbers (transmit byte count) and the scale of the time axis:

Now for Mitogen, demonstrating vastly more conservative use of the network:

The SSH connection setup is clearly visible in this graph, accounting for about the first 300ms on the time axis. Additional excessive roundtrips are visible as Mitogen waits for its command-line to signal successful first stage bootstrap before uploading the main implementation, and 2 subsequent roundtrips first to fetch
mitogen.sudomodule followed by themitogen.mastermodule. Eliminating module import roundtrips like these will probably be an ongoing battle, but there is a clean 80% solution that would apply in this specific case I just haven't gotten around to implementing yet.The fine curve representing repeated executions of
/bin/trueis also visible: each bump in the curve is equivalent to Ansible's huge data uploads from earlier, but since Mitogen caches code in RAM remotely, unlike Ansible it doesn't need to reupload everything for each call, or start a new Python process, or rewrite a ZIP file on disk, or .. etc.Finally one last graph, showing Mitogen with the execution loop moved to the remote machine. All the latency induced by repeatedly invoking
/bin/truefrom the local machine has disappeared.
The Less Ugly
Ansible's pipelining mode is much better, and somewhat resembles Mitogen's own bootstrap process. Here the templatized initial script is fed directly into the target Python interpreter, however they immediately deviate since Ansible starts by extracting the embedded ZIP file per step 8 above, and discarding all the code it uploaded once the playbook step completes, with no effort made to preserve either the Python processes spawned, or the significant amount of uploaded module code for each step.
Pipelining mode is a huge improvement, however it still suffers from making use of the SSH stdio pipeline only once (which was expensive to setup, even with multiplexing enabled), the destination Python interpreter only once (usually ~100ms+ per invocation), and as mentioned repeatedly, no caching of code in the target, not even on disk.
When Mitogen is executing your Python function:
- it executes SSH with a single Python command-line,
- then it waits for that command-line to report
"EC0"on stdout, - then it writes a copy of itself over the SSH pipe,
- meanwhile the remote Python interpreter forks into two processes,
- the first re-execs itself to clear the huge Python command-line passed over SSH, and resets
argv[0]to something descriptive, - the second signals
"EC0"and waits for the parent context to send 7KiB worth of Mitogen source, which it decompresses and feeds to the first before exitting, - the Mitogen source reconfigures the Python module importer, stdio, and logging framework to point back into itself, then starts a private multiplexer thread,
- the main thread writes
"EC1"then sleeps waiting forCALL_FUNCTIONmessages, - meanwhile the multiplexer routes messages between this context's main thread, the parent, and any child contexts, and waits for something to trigger shutdown.
- then it waits for the remote process to report
"EC1", - then it writes a
CALL_FUNCTIONmessage which includes the target module, class, and function name and parameters,- the slave receives the
CALL_FUNCTIONmessage and begins execution, satisfying in-RAM module imports using the connection to the parent context as necessary.
- the slave receives the
On subsequent invocations of your Python function, or other functions from the same module, only steps 3.6, 5, and 5.1 are necessary.
This all sounds fine and dandy, but how can I use it?
I'm working on it! For now my goal is to implement enough functionality so that Mitogen can be made to work with Ansible's process model. The first problem is that Ansible runs playbooks using multiple local processes, and has no subprocess<->host affinity, so it is not immediately possible to cache Mitogen's state for a host. I have a solid plan for solving that, but it's not yet implemented.
There are a huge variety of things I haven't started yet, but will eventually be needed for more complex setups:
-
Getting Started Documentation: it's missing.
-
Asynchronous connect(): so large numbers of contexts can be spawned in reasonable time. For, say, 3 tiers targeting a 1,500 node network connecting in 30 seconds or so: a per-rack tier connecting to 38-42 end nodes, a per-quadrant tier connecting to 10 or so racks, a single box in the datacentre tier for access to a management LAN, reducing latency and caching uploaded modules within a datacenter's network, and the top-level tier which is the master program itself.
-
Better Bootstrap, Module Caching And Prefetching: currently Mitogen is wasting network roundtrips in various places. This makes me lose sleep.
-
General Robustness: no doubt with real-world use, many edge cases, crashes, hangs, races and suchlike will be be discovered. Of those, I'm most concerned with ensuring the master process never hangs with CTRL+C or
SIGTERM, and in the case of master disconnect, orphaned contexts completely shut down 100% of the time, even if their main thread has hung. -
Better Connection Types: it should at least support SSH connection setup over a transparently forwarded TCP connection (e.g. via a bastion host), so that key material never leaves the master machine. Additionally I haven't even started on Windows support yet.
-
Security Audit: currently the package is using cPickle with a highly restrictive class whitelist. I still think it should be possible to use this safely, but I'm not yet satisfied this is true. I'd also like it to optionally use JSON if the target Python version is modern enough. Additionally some design tweaks are needed to ensure a compromised slave cannot use Mitogen to cross-infect neighbouring nodes.
-
Richer Primitives: I've spent so much effort keeping the core of Mitogen compact that overall design has suffered, and while almost anything is possible using the base code, often it involves scrobbling around in the internal plumbing to get things working. Specifically I'd like to make it possible to pass
Contexthandles as RPC parameters, and generalise thefakesshcode so that it can handle other kinds of forwarding (e.g. TCP connections, additional UNIX pipe scenarios). -
Tests. The big one: I've only started to think about tests recently as the design has settled, but so much system-level trickery is employed, always spread out across at least 2 processes, that an effective test strategy is so far elusive. Logical tests don't capture any of the complex OS/IO ordering behaviour, and while typical integration tests would capture that, they are too coarse to rely on for catching new bugs quickly and with strong specificity.
Why are you writing about this now?
If you read this far, there's a good chance you either work in infrastructure tooling, or were so badly burned by your experience there that you moved into management. Either way, you might be the person who could help me spend more time on this project. Perhaps you are on a 10-person team with a budget, where 30% of the man-hours are being wasted on Ansible's connection latency? If so, you should definitely drop me an e-mail.
The problem with projects like this is that it is almost impossible to justify commercially, it is much closer to research than product, and nobody ever wants to pay for that. However, that phase is over, the base implementation looks clean and feels increasingly solid, my development tasks are becoming increasingly target-driven, and I'd love the privilege to polish up what I have, to make contemporary devops tooling a significantly less depressing experience for everyone involved.
If you merely made it to the bottom of the article because you're interested or have related ideas, please drop me an e-mail. It's not quite ready for the prime time, but things work more than sufficiently that early experiementation is probably welcome at this point.
Meanwhile I will continue aiming to make it suitable for use with Ansible, or perhaps a gentle fork of Ansible, since its internal layering isn't the greatest.
- First it scans