-
Kickstarting free software: one week later
It’s been an incredibly intense first week crowdfunding the Mitogen extension for Ansible involving far more effort than anticipated, where I have worked almost flat out from waking until the early hours just to ensure any queries are answered thoroughly. I cannot complain, because it has been so much fun that I’d change almost nothing of the experience, and already the campaign has reached 46% from the exposure it received.
As a recap Mitogen is a library for writing distributed programs that require zero deployment, with the prototype extension implementing an architectural change that vastly improves Ansible’s performance in common scenarios, laying a framework to extend this advantage far beyond simple overhead reduction.
Initial testers
A great deal of work has simply been staying on top of bug reports and ensuring experiences with the prototype are solid – for each report from one tester, we can assume 10 more hit the same bug but did not or could not report it.
Of the many reports received, I have addressed almost all of them promptly. Some fabulous bugs have been found and fixed along with one report via Reddit of a performance improvement so fantastical that it exceeds even my most contrived overhead-heavy example:
"With mitogen my playbook runtime went from 45 minutes to just under 3 minutes. Awesome work!"
This is a common theme – anywhere with_items appears, Mitogen has the most profound impact. The obvious reason is that during loops the same module is executed repeatedly, and after one iteration is guaranteed to be compiled and ready on the target.
So many lessons!
Developing the campaign from a thought exercise one idle Sunday evening into an actually practical project has taken a lot of work – far more than I anticipated, and at almost every step I have learned something novel. This is all reuseable knowledge for anyone attempting a similar project in future, and I will write it up as time permits.
Regardless of outcomes the campaign has already proven one very exciting result: real users will stake real money towards something as seemingly mundane as free infrastructure, and I think that’s beyond amazing. In a world content to throw millions of dollars at junk ICOs almost weekly, crowdfunding free software seems to me a practice that should happen far more often.
Thank you
I wish to thank everyone for the support shown thus far, and I’d encourage you to consider tapping that Ansible user you know on the shoulder to let them know about the project. For those working close to infrastructure consulting, please consider using the final week to corner your boss regarding associating your company logo with a sexy project that promises to receive many eyeballs over the coming years.
Thanks for reading!
David. -
Quadrupling Ansible performance with Mitogen
[tl;dr: the Mitogen extension for Ansible exists today and it’s as awesome as I promised, but I want to push things much further. If you value free time, this project needs your support]
Allegedly on site as a developer, two summers ago I found myself in a situation you are no doubt familiar with, where despite preferences unrelated problems inevitably gravitate towards whoever can deal with them. Following an exhausting day spent watching a dog-slow Ansible job fail repeatedly, one evening I dusted off a personal aid to help me relax: an ancient, perpetually unfinished hobby project whose sole function until then had simply been to remind me things can always improve.

Something of a miracle had struck by the early hours of next morning, as almost every outstanding issue had been solved, and to my disbelief the code ran reliably. 18 months later and for the first time in living memory, I am excited to report delivery of that project, one of sufficient complexity as to have warranted extreme persistence - in this case from concept to implementation, over more than a decade.
The miracle? It comes in the form of Mitogen - a tiny Python library you won’t have heard of, but I hope as an Ansible user you will soon eternally be glad for, on discovering ansible-playbook now completes in very reasonable time even in the face of deeply unreasonable operating conditions.
Mitogen is a library for writing distributed programs that require zero deployment, specifically designed to fit the needs of infrastructure software like Ansible. Without upfront configuration it supports any UNIX machine featuring an installed Python interpreter, which is to say almost all of them. While the concept is hard to explain - even to fellow engineers, its value is easy to grasp:

This trace shows two Ansible runs of a basic 100-step playbook over a 1 ms latency network against a single target host. The first run employs SSH pipelining, Ansible’s current most optimal configuration, where it consumes almost 4.5 Mbytes network bandwidth in a running time of 59 secs.
The second uses the prototype Mitogen extension for Ansible, with a far more reasonable 90 Kbytes consumed in 8.1 secs. An unmodified playbook executes over 7 times faster while consuming 50x less bandwidth.
Less than half the CPU time was consumed on the host machine, meaning that by one metric it should handle at least twice as many targets. Crucially no changes were required to the target machine, including new software or nasty on-disk caches to contend with.

While only pure overhead is measured above, the benefits very much extend to real-world scenarios. See the documentation and issue #85 (4.2x time, 3.1x CPU) for examples.
How is this possible?
Mitogen is perhaps most easily described as a kind of network-capable fork() on steroids. It allows programs to establish lazily-loaded duplicates on remote hosts, without requiring any upfront remote disk writes, and to communicate with those copies once they exist. The copies can in turn recursively split to produce further children - with bidirectional message routing between every copy handled automatically.
In the context of Ansible, unlike with SSH pipelining where up to one SSH invocation, sudo invocation and script compilation are required for every playbook step, and with all scripts re-uploaded for each step, with Mitogen only one of each exists per target for the duration of the playbook run, with all code cached in RAM between steps. Absolutely everything is reused, saving 300-800 ms on every step.
The extension represents around a week’s work, replaces hundreds of lines of horrid shell-related code in Ansible, and is already at the point where on one real-world playbook, Ansible is only 2% slower than equivalent SSH commands. Presently connection establishment is single-threaded, so the prototype is only good for a few hosts, but rest assured this limitation’s days are numbered.
Not just a speed up, a paradigm shift you’ll adore

If this seems impressive and couldn’t be improved upon, prepare for some deep shocks. You can think of the extension not just as a performance improvement, but something of a surreptitious beachhead from which I intend to thoroughly assault your sense of reality.
This performance is a side effect of a far more interesting property: Ansible is no longer running on just the host machine, but temporarily distributed throughout the target network for the duration of the run, with bidirectional communication between all pieces, and you won’t believe the crazy functionality this enables.
What if I told you it were possible not only to eliminate that final 2%, but turn it sharply negative, while simultaneously reducing resource consumption? “Surely Ansible can’t execute faster than equivalent raw SSH commands?” You bet it can! And if you care about such things, this could be yours by Autumn. Read on..
Pushing brains into the ether, no evil agents required

As I teased last year, Ansible takes its name from a faster-than-light communication device from science fiction, yet despite these improvements it is still fundamentally bound by the speed with which information physically propagates. Pull and agent-based tooling is strongly advantageous here: control flow occurs at the same point as the measurements necessary to inform that flow, and no penalty is incurred for traversing the network.
Today, reducing latency in Ansible means running it within the target network, or in pull mode, where the playbook is stored on the target alongside for example, secrets for decrypting any vaults, and the hairy mechanics required to keep that in sync and executing when appropriate. This is a far cry from the simplicity of tapping
ansible-playbook live.ymlon your laptop, and so it is an option of last resort.What would be amazing is some hybrid where we could have the performance and scaleability benefits of pull, combined with the stateless simplicity of push, without introducing dedicated hosts or permanent caches and agents running on the target machines, that amount to persistent intermediate state and introduce huge headaches of their own, all without sacrificing the fabulous ability to shut everything down with a simple CTRL+C.
The opening volley: connection delegation
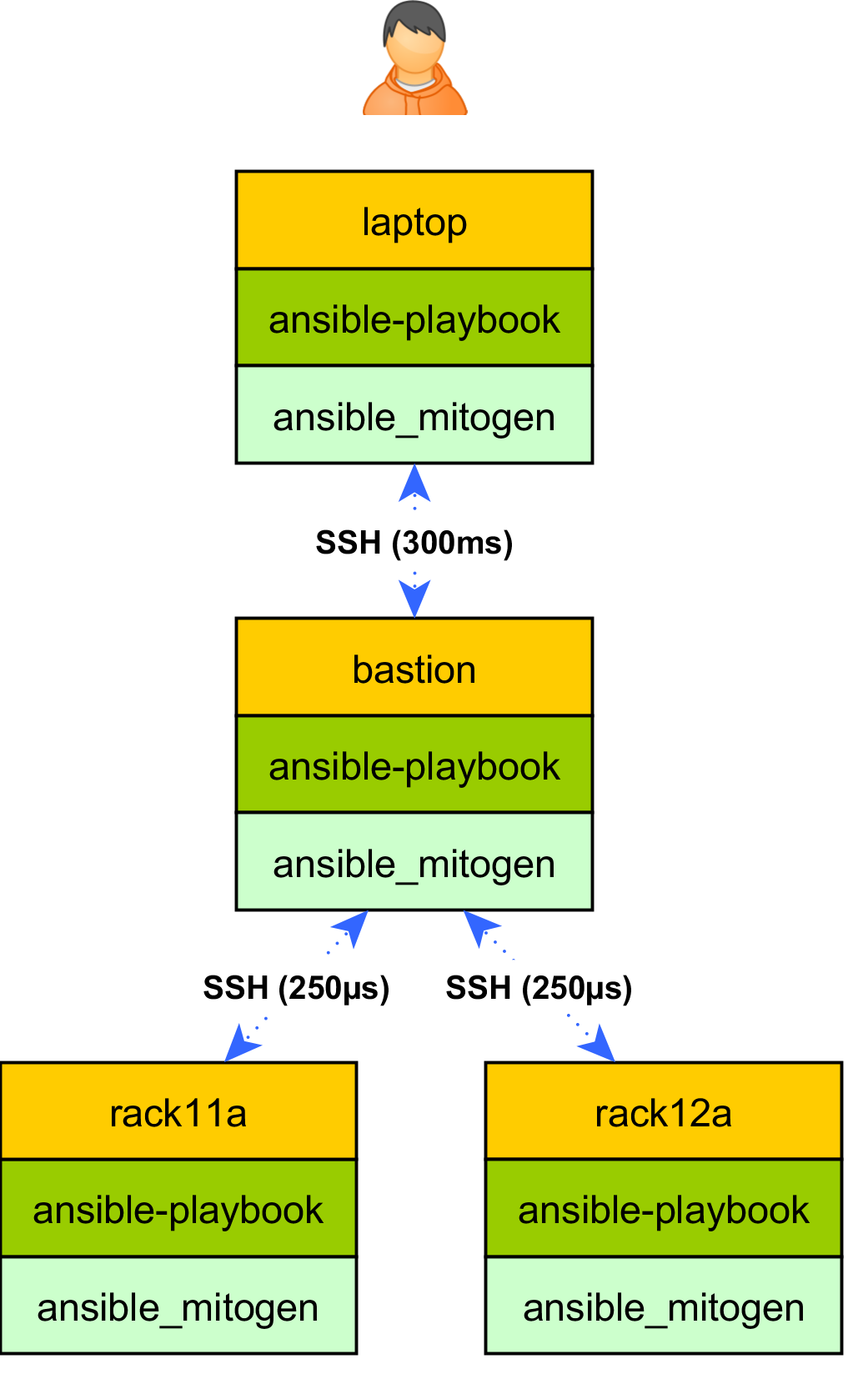
As a first step to exploiting previously impossible functionality, I will enhance the extension to support delegating connection establishment to a machine on the target network, avoiding the cost of establishing hundreds of SSH connections over a low throughput, high latency network link.
Unlike with SSH proxying, this has the huge benefit of caching and serving Ansible code from RAM on the intermediary, avoiding uploading approximatey 50KiB of code for every playbook step, and ensuring those cached responses are delivered over the low latency LAN fabric on the target network. For 100 target machines, this replaces the transmission of 5 Mbytes of data for every playbook step with on the order of kilobytes worth of tiny remote procedure calls.
All the Mitogen-side infrastructure for this exists today, and is already used to implement become support. It could be flipped on with a few lines of code in the Ansible extension, but there are a few more importer bugs to fix before it’ll work perfectly.
Finally as a reminder, since Mitogen operates recursively delegation also operates recursively, with code caching and connection establishment happening at each hop. Not only is this useful for navigating slow links and complicated firewall setups, as we’ll see, it enables some exciting new scenarios.
Asynchronous Connect
Ansible is intended to manage many machines simultaneously, and while the extension’s improvements presently work well for single-machine playbooks, that is all but a niche application for many users.
Having the newfound ability to delegate connection establishment to an intermediary on the target network, far away from our laptop’s high latency 3G connection, and with the ability to further sub-delegate from that intermediary, we can implement a divide and conquer strategy, forming a large tree comprising the final network of target machines for the playbook run, with responsibility for caching and connection multiplexing evenly divided across the tree, neatly avoiding single resource bottlenecks.
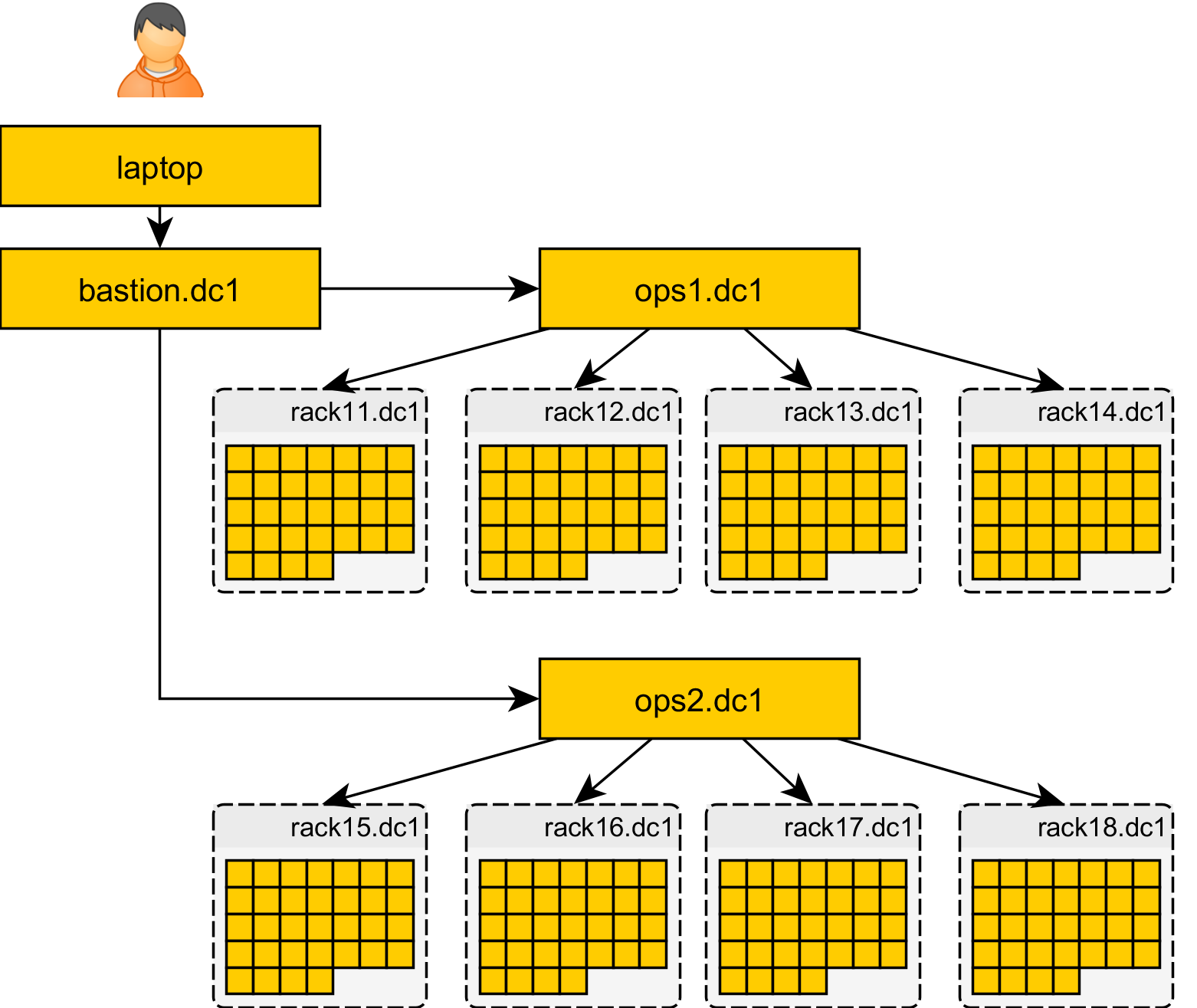
I will rewrite Mitogen’s connection establishment to be asynchronous: creation of many downstream connections can be scheduled in parallel, with the ability to enqueue commands prior to completion, including recursive commands that would cause those connections to in turn be used as intermediaries.
The cost of establishing connections should become only the cost of code upload (~50KiB) and the latency of a single SSH connection per tree layer, as connections at each layer occur in parallel. For an imaginary 1,700 node cluster split into quarters of 17 racks and 25 nodes per rack, connection via a 300 ms 3G network should complete in well under 15 seconds.
Topology-aware file synchronization
So you have a playbook on your laptop deploying a Django application via the synchronize module, to 100 Ubuntu machines running in a datacentre 300 ms away. Each run of the playbook entails a groan followed by a long walk, as a 3.8 second rsync run is invoked 100 times via your 3G connection, just to synchronize a 3 Mbyte asset the design team won’t stop tweaking. Not only are there 6 minutes of roundtrips buried in those invocations, but that puny 3G connection is forced to send a total of 300 Mbytes toward the target network.
What is the point of continually re-sending that file to the same set of machines in some far-off network? What if it could be uploaded exactly once, then automatically cached and redistributed within the target network, producing exactly one upload per layer in the hierarchy:
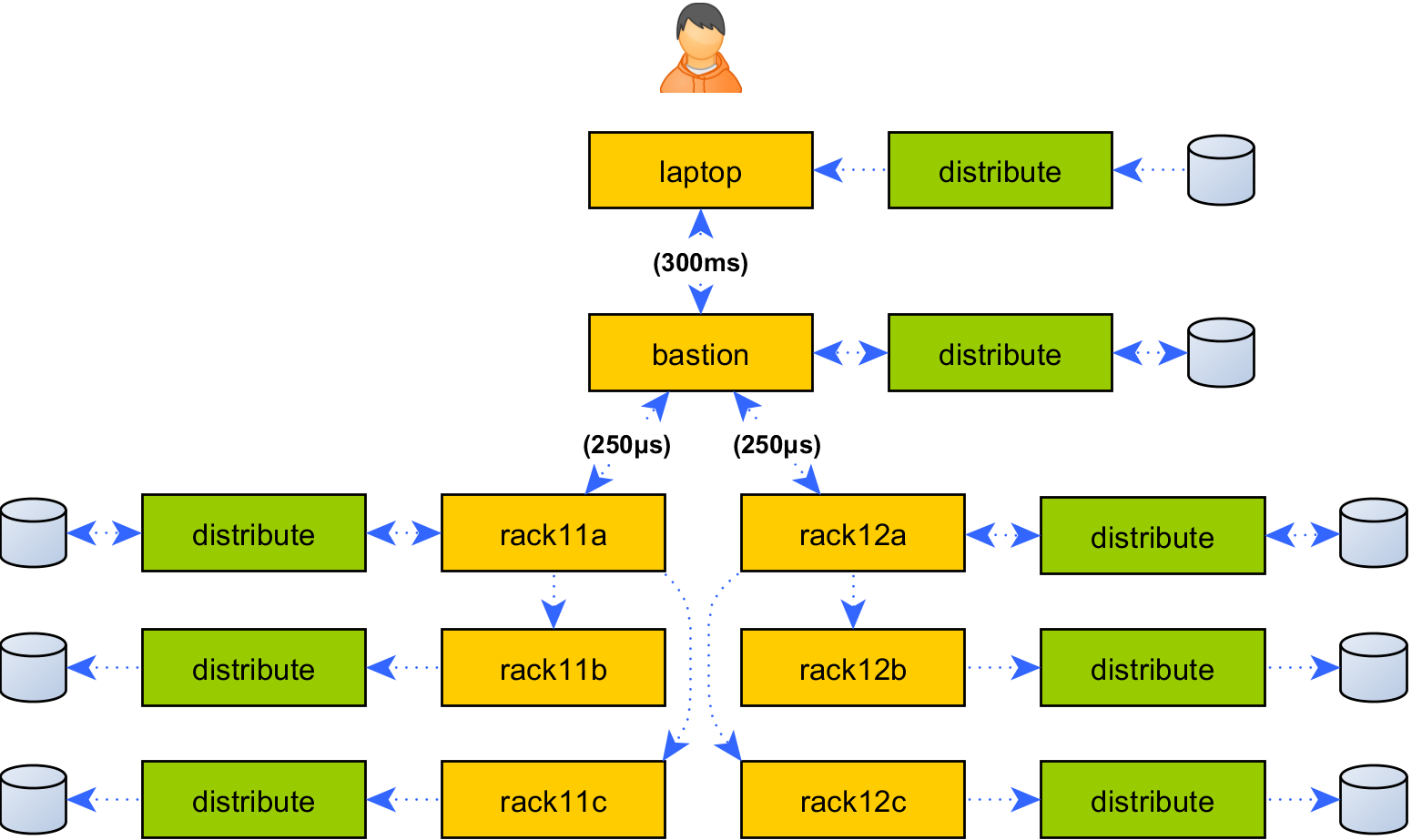
Why stop at delegating connection establishment and module caching? Now we have a partial copy of Ansible within the network, nothing prevents implementing all kinds of smarts. Here is another feature that is a cinch to build once bidirectional communication exists between topology-aware code, which the prototype extension already provides today.
Generalized forwarding
After a brutal 4 hour meeting involving 10 executives our hero Bob, Senior Disaster Architect III, emerges bloodstained yet victorious against the tyrannical security team, as his backends can talk with impunity to the entire Internet just so
apt-getcan reachpackages.debian.orgfor the 15 seconds Bob’s daily Ansible CI job requires.That evening, having regaled his giddy betrothed (HR Coordinator II) with heroic story of war, Bob catches a brief yet chilling glimmer of doubt for all that transpired. “Was there another way?” he sleepily ponders, before succumbing to a cosier battle waged by those fatigued and heavy eyelids. Suddenly aware again, Bob emerges bathed in a mysterious utopian dreamscape where CI jobs executed infinitely quickly, war and poverty did not exist, and the impossible had always been possible.
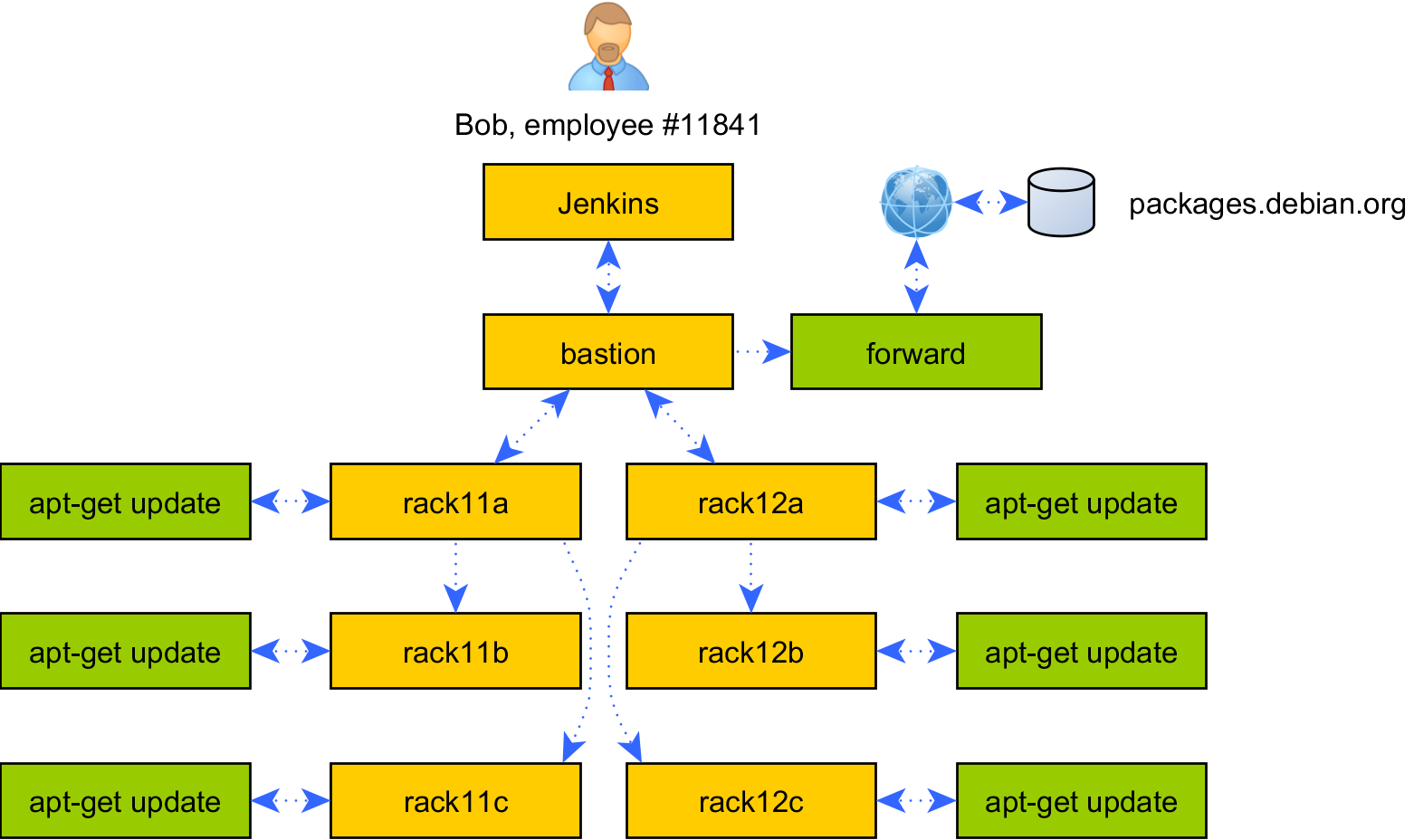
Building on Mitogen’s message routing, forwarding all kinds of pipes and network sockets becomes trivial, including schemes that would allow exposing a transient, locked down HTTP proxy to Bob’s
apt-getinvocation only for as long as necessary, all with a few lines of YAML in a playbook.While this is already possible with SSH forwarding, the hand-configuration involved is messy, and becomes extremely hairy when the target of the forward is not the host machine. My initial goal is to support forwarding of UNIX and TCP sockets, as they cover all use cases I have in mind. Speaking of which..
Topology-aware Git pull
Another common security fail seen in Ansible playbooks is to call Git directly from target machines, including granting those machines access to a Git server. This is a horrid violation: even read-only access implies the machine needs permanent firewall rules that shouldn’t exist, just for the scant moments a pull is in progress. Granting backends access to a site as complex as GitHub.com, you may as well abandon all outbound firewalling, as this is enough for even the puniest script kiddy to exfiltrate a production database.
What if Git could run with the permissions of the local Ansible user, on the user’s own machine, and be served efficiently to the target machines only for the duration of the push, faster than 100 machines talking to GitHub.com, and only to the single read-only repository intended?
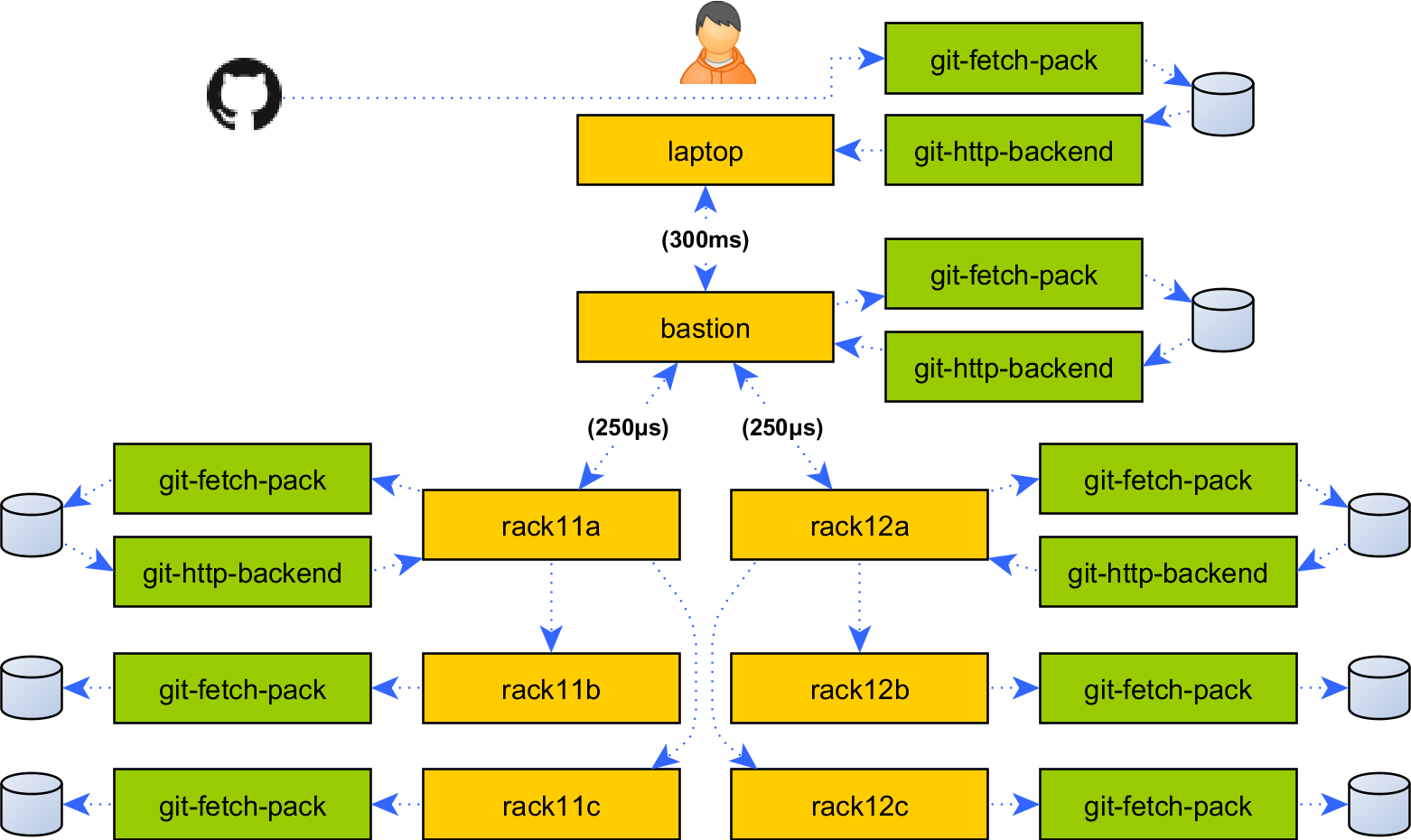
Building on generalized forwarding, topology-aware Git repeats all the caching and single-upload tricks of file synchronization, but this time implementing the Git protocol between each node.
In the scheme I will implement, a single round-trip is necessary for git-fetch-pack to pull just the changed objects from the laptop over the high latency 3G link, before propagating at LAN speeds throughout the target network, with git-ls-remote output delivered as part of the message that initiates the pull. Not only is the result more efficient than a normal git-pull, but backends no longer require network access to Git.
The final word: Inversion of control
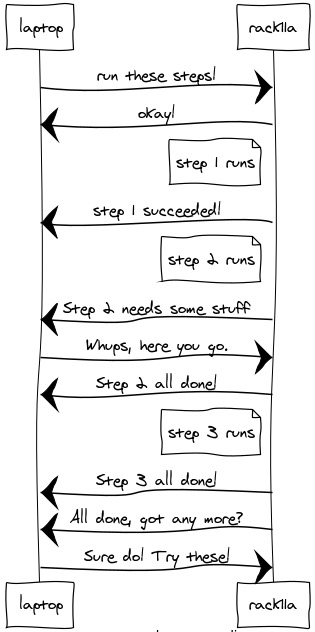
Remember we talked about making Ansible run faster than equivalent SSH commands? Well, today Ansible requires one network round-trip per playbook step, so just like SSH, it must pay the penalty for every round-trip unless something gives, and that something is the partial delegation of control to the target machine itself.
With inversion of control, the role of
ansible-playbooksimply becomes that of shipping code and selective chunks of data to target machines, where those machines can execute and make control decisions without necessitating a conversation with the master after each step, just to figure out what to execute next.Ansible has all the framework to enable implementing this today, by significantly extending the prototype extension’s existing strategy plug-in, and teaching it how to automatically send and wait on batches of tasks, rather than on single tasks at a time.
Aside from improved performance, the semantics of the existing
linearstrategy will be preserved, and playbooks need not be changed to cope: on the target machine tasks will not suddenly begin running concurrently, or in any order different to previously.App-level connection persistence
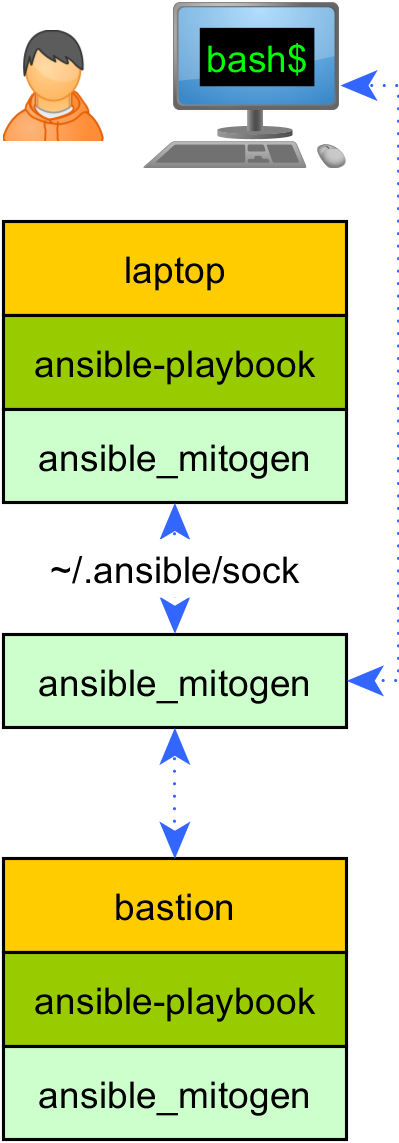
As a final battle against latency during playbook development and debugging, I will support detaching the connection tree from
ansible-playbookon exit, and teach the extension to reuse it at startup. This will reduce the overhead of repeat runs, especially against many targets, to the order of hundreds of milliseconds, as no new SSH connections, module compilations or code uploads are required.Connection persistence opens the floodgates for adding sweet new tooling, although I’m not sure how desirable it is to expose an implementation detail like this forever, while also extending the interface provided by Ansible itself. As a simple example, we could provide an
ansible-sshtool that reuses the connection tree along with Ansible’s tunnelling, delegation, dynamic inventory and authentication configuration to forward a pipe to a remote shell.Ansible has over 28,500 stars on GitHub, representing just those users who have a GitHub account and ever thought to star it, and appears to grow by 150 stars per week. Around London the going rate to hire one user is $100/hour, and conservatively, we could expect that user is trotting out a 15 minute run of
ansible-playbook live.ymlat least once per week.We can expect that if Ansible is running merely twice as slowly as necessary, 7.5 minutes of that run is lost productivity, and across those 28,500 users, the economic cost is in the region of $356,250 per invocation or $17,100,000 per year. In reality the average user is running Ansible far more often, including thousands of times per minute under various CI systems worldwide, and those runs often last far longer than 15 minutes, but I’d recommend that mental guesstimation is left as an exercise to readers who are already blind drunk.
The future is beautiful if you want it to be

My name is David, and nothing jinxes my day quite like slow tooling. I have poured easily 500 hours in some form into this project over a decade and on my own time. The project has now reached an inflection point where the fun part is over, the science is done and the effect is real, and only a small, highly predictable set of milestones remain to deliver what I hope you agree is a much brighter future.
Before reading I doubt you would have believed it possible to provide the features described without a complex infrastructure running in the target network, now I hope you’ll join me in disproving one final impossibility.
While everything here will exist in time, it cannot exist in 2018 without your support, and that’s why I’d like to try something crazy, that would allow me to devote myself to delivering a vastly improved daily routine for thousands of people just like you and me.
You may have guessed already: I want you to crowdfund awesome tooling.
What value would you place on an extra productive hour every working week? In the UK that’s an easy question: it’s around $4,800 per year. And what risk is there to contributing $100 to an already proven component? I hope you’ll agree this too is a no-brainer, both for you and your employer.
To encourage success I’m offering a unique permanent placement of your brand on the GitHub repository and documentation. Funds will be returned if the minimum goal cannot be reached, however just 3 weeks are sufficient to ensure a well tested extension, with my full attention given to every bug, ready to save many hours right on time to enjoy the early sunlight of Spring.
Totalling much less than the economic damage caused by a single run of today’s Ansible, the grand plan is divided into incrementally related stretch goals. I cannot imagine this will achieve full funding, but if it does, as a finale I’ll deliver a feature built on Ansible that you never dreamed possible.
What will that be? Pledge today if you’d like to find out.
Combating obsolescence in our beloved tools
As a modern area deployment tooling is exposed to the ebb and flow of the software industry far more than typical, and unexpected disruption happens continuously. Without ongoing evolution, exposure to buggy and unfamiliar new tooling is all but guaranteed, with benefits barely justifying the cost of their integration. As we know all too well, rational ideas like cost/benefit rarely win the hearts of buzzword-hungry and youthful infrastructure teams, so counterarguments must be presented another way.
As a recent example there is growing love for mgmt, which is designed from the outset as an agent-based reactive distributed system, much as Mitogen nudges Ansible towards. However unlike mgmt, Ansible preserves its zero-install and agentless nature, while laying a sound framework for significantly more exciting features. If that alone does not win loyalty, we’re at least guaranteed that every migration-triggering new feature implemented in such systems can be headed off with minimal effort, long into the foreseeable future.
David.