-
Much ado about latency: Mitogen and the BFG9000 of import hooks
After a long winter break from recreational programming, over the past days I finally built up steam and broke a chunk of new ground on Mitogen, this time growing its puny module forwarder into a bona fide beast, ready to handle almost any network condition and user code thrown at it.

No adversary is a match for the BFG Recap
Mitogen is a library for executing parts of a Python program in a remote context, primarily over
sudoand SSH connections, and establishing bidirectional communication with those parts. Targeting infrastructure applications, it requires no upfront configuration of target machines, aside from an SSH daemon and Python 2.x interpreter, which is the default for almost every Linux machine found on any conceivable network.The target need not possess a writeable filesystem, code is loaded dynamically on demand, and execution occurs entirely from RAM.
How Import Works
To implement dynamic loading, child Python processes (“contexts”) have a PEP-302 import hook installed that causes attempts to import modules unavailable locally to automatically be served over the network connection to the parent process. For example, in a script like:
import mitogen import requests def get_url(url): return requests.get(url).text @mitogen.main() def main(router): host = router.ssh(hostname='k3') print host.call(get_url, 'https://www.google.com/')If the
requestspackage is missing on the hostk3, it will automatically be copied and imported in RAM, without requiring upfront configuration, or causing or requiring writes to the remote filesystem.
Kathmandu to Paris via 3G: serious business So far, so good. Just one hitch
While the loader has served well over the library’s prototypical life (which in real time, is approaching 12 years!), it has always placed severe limits on the structure of the loaded code, as each additional source file introduced one network round-trip to serve it.
Given a relatively small dependency such as Kenneth Reitz' popular Requests package, comprising 17 submodules, this means 17 additional network round-trips. While that may not mean much over a typical local area network segment where roundtrips are measured in microseconds, it quickly multiplies over even modest wide-area networks, where infrastructure tooling is commonly deployed.
For a library like Requests, 17 round-trips amounts to 340ms latency over a reasonably local 20ms link, which is comfortably within the realms of acceptable, however over common radio and international links of 200ms or more, already this adds at least 3.4 seconds to the startup cost of any Mitogen program, time wasted doing nothing but waiting on the network.
Sadly, Requests is hardly even the biggest dependency Mitogen can expect to encounter. For testing I chose django.db.models as a representative baseline: heavily integrated with all of Django, it transitively imports over 160 modules across numerous subpackages. That means on an international link, over 30 seconds of startup latency spent on one dependency.
It is worth note that Django is not something I’d expect to see in a typical Mitogen program, it’s simply an extraordinarily worst-case target worth hitting. If Mitogen can handle
django.db.models, it should cope with pretty much anything.Combining evils, over an admittedly better-than-average Nepali mobile data network, and an international link to my
IRC boxmail server in Paris,django.db.modelstakes almost 60 seconds to load with the old design.In the real world, this one-file-per-roundtrip characteristic means the current approach sucks almost as much as Ansible does, which calls into doubt my goal of implementing an Ansible-trumping Ansible connection plug-in. Clearly something must give!

50.35 seconds and hundreds of roundtrips spent transferring django.db.modelsfrom Kathmandu to Paris via 3G. Despite a fast link, throughput averages 13KiB/sec and never exceeds 45KiB/sec. Well over half of the 989 frames sent are wasted on signalling (Y=0)Trying harder
Over the years I discarded many approaches for handling this latency nightmare:
- Having the user explicitly configure a module list to deliver upfront to new contexts, which sucks and is plainly unmaintainable.
- Installing a PEP-302 hook in the master in order to observe the import graph, which would be technically exciting, but likely to suck horribly due to fragility and inevitable interference with real PEP-302 hooks, such as py2exe.
- Observing the import graph caused by a function call in a single context, then using it to preload modules in additional contexts. This seems workable, except the benefit would only be felt by multiple-child Mitogen programs. Single child programs would continue to pay the latency tax.
- Variants of 2 and 3, except caching the result as intermediate state in the master’s filesystem. Ignoring the fact persistent intermediate state is always evil (a topic for later!), that would require weird and imperfect invalidation rules, which means performance would suck during development and prototyping, and bugs are possible where state gets silently wedged and previously working programs inexplicably slow down.
Finally last year I settled on using static analysis, and restricting preloading at package boundaries. When a dependency is detected in a package external to the one being requested, it is not preloaded until the child has demonstrated, by requesting the top-level package module from its parent, that the child lacks all of the submodules contained by it.
This seems like a good rule: preloading can occur aggressively within a package, but must otherwise wait for a child to signal a package as missing before preemptively wasting time and bandwidth delivering code the child never needed.
As a final safeguard, preloading is restricted to only modules the master itself loaded. It is not sufficient for an
importstatement to exist: surrounding conditional logic must have caused the module to be loaded by the master. In this manner the semantics of platform, version-specific and lazy imports are roughly preserved.Syntax tree hell
Quite predictably, after attempting to approach the problem with regexes, I threw my hands up on realizing a single regex may not handle every possible import statement:
import aimport a as bfrom a import bfrom a import b as cfrom a import (b, c, d)
I gleefully thought I’d finally found a use for the compiler and ast modules, and these were the obvious alternative to avoiding the rats nest of multiple regexes. Not quite. You see, across Python releases the grammar has changed, and in lock-step so have the representations exported by the
compilerandastmodules.Adding insult to injury: neither module is supported through every interesting Python version. I have seen Python 2.4 deployed commercially as recently as summer 2016, and therefore consider it mandatory for the kind of library I want on my toolbelt. To support antique and chic Python alike, it was necessary to implement both approaches and select one at runtime. Many might see this is an opportunity to drop 2.4, but “just upgrade lol” is never a good answer while maintaining long shelf-life systems, and should never be a a barrier to applying a trusted Swiss Army Knife.
After some busy days last September, I had a working scanner built around syntax trees, except for a tiny problem: it was ridiculously slow. Parsing the 8KiB
mitogen.coremodule took 12ms on my laptop, which multiplied up is over a second of CPU burnt scanning dependencies for a package like Django. If memory serves, reality was closer to 3 seconds: far exceeding the latency saved while talking to a machine on a LAN.Sometimes hacking bytecode make perfect sense
I couldn’t stop groaning the day I abandoned ASTs. As is often true when following software industry best practice, we are left holding a decomposing trout that, while technically fulfilling its role, stinks horribly, costs all involved a fortune to support and causes pains worse than those it was intended to relieve. Still hoping to avoid regexes, I went digging for precedent elsewhere in tools dealing with the same problem.
That’s when I discovered the strange and unloved modulefinder buried in the standard library, a forgotten relic from a bygone era, seductively deposited there as a belated Christmas gift to all, on a gloomy New Year’s Eve 2002 by Guido’s own brother. Diving in, I was shocked and mesmerized to find dependencies synthesized by recompiling each module and extracting IMPORT_FROM opcodes from the compiled bytecode. Reimplementing a variant, I was overjoyed to discover
django.db.modelstransitive dependencies enumerated in under 350ms on my laptop. A workable solution!The solution has some further crazy results:
IMPORT_FROMhas barely changed since the Python 2.4 days, right through to Python 3.x. The same approach works everywhere, including PyPy, which uses the same format, which makes this more portable than theastandcompilermodules!Coping with concurrency
Now a mechanism exists to enumerate dependencies, we need a mode of delivery. The approach used is simplistic, and (as seen later), will likely require future improvement.
On receiving a GET_MODULE message from a child, a parent (don’t forget, Mitogen operates recursively!) first tries to satisfy the request from its own cache, before forwarding it upwards towards the master. The master sends LOAD_MODULE messages for all dependencies known to be missing from the child before sending a final message containing the module that was actually requested. Since contexts always cache unsolicited
LOAD_MODULEmessages from upstream, by the time the message arrives for the requested module, many dependencies should be in RAM and no further network roundtrips requesting them are required.Meanwhile for each stream connected to any parent, a set of module names ever delivered on that stream are recorded. Each parent is allowed to ignore any
GET_MODULEfor which a correspondingLOAD_MODULEhas already been sent, preventing a race between in-flight requests causing the same module to ever be sent twice.This places the onus on downstream contexts to ensure the single
LOAD_MODULEmessage received for each distinct module always reaches every interested party. In short,GET_MODULEmessages must be deduplicated and synchronized not only for any arriving from a context’s children, but also from its own threads.Some further gory details are in the docs
Pretty pictures
And finally the result. For my test script, the total number of roundtrips dropped from 166 to 13, one of which is for the script itself, and 3 negative requests for extension modules that cannot be transferred. That leaves, bugs aside, 9 roundtrips to transfer the most obscene dependency I could think of.
One more look at the library’s network profile. Over the same connection as previously, the situation has improved immensely:

570 packets sending Django 7,231km over 3G in 16.47 seconds. Throughput averages 38.6KiB/sec and peaks at 2.7MiB/sec Not only is performance up, but the number of frames transmitted has dropped by 42%. That’s a 42% fewer changes of connection hang due to crappy WiFi!
One final detail is visible: around the 10 second mark, a tall column of frames is sent with progressively increasing size, almost in the same instant. This is not some bug, it is Path MTU Discovery (PMTUD) in action. PMTUD is a mechanism by which IP subprotocols can learn the maximum frame size tolerated by the path between communicating peers, which in turn maximizes link efficiency by minimizing bandwidth wasted on headers. The size is ramped up until either loss occurs or an intermediary signals error via ICMP.
Just like the network path, PMTUD is dynamic and must restart on any signal indicating network conditions have changed. Comparing this graph with the previous, we see one final improvement as a result of providing the network layer enough data to do its job: PMTUD appears restart much less frequently, and the stream is pegged at the true path MTU for much longer.
Futures
Aside from simple fixes to reduce wasted roundtrips for extension modules that can’t be imported, and optional imports of top-level packages that don’t exist on the master, there are two major niggles remaining in how import works today.
The first is an irritating source of latency present in deep trees: currently it is impossible for intermediary nodes satisfying GET_MODULE requests for children to streamily send preloaded modules towards a child until the final LOAD_MODULE arrives at the intermediary for the module actually requested by the child. That means preloading is artificially serialized at each layer in the tree, when a better design would allow it to progress concurrent to the
LOAD_MODULEmessages still in-flight from the master.This will present itself when doing multi-machine hops where links between the machines are slow or suffer high latency. It will also be important to fix before handling hundreds to thousands of children, such as should become practical once asynchronous connect() is implemented.
There are various approaches to tweaking the design so that concurrency is restored, but I would like to let the paint dry a little on the new implementation before destablizing it again.
The second major issue is almost certainly a bug waiting to be discovered, but I’m out of energy to attack it right now. It relates to complex situations where many children have different functions invoked in them, from a complex set of overlapping packages. In such cases, it is possible that a
LOAD_MODULEfor an unrelatedGET_MODULEprematurely delivers the final module from another import, before it has had all requisite modules preloaded into the child.To fix that, the library must ensure the tree of dependencies for all module requests are sent downstream depth-first, i.e. it is never possible for any module to appear in a
LOAD_MODULEbefore all of its dependencies have first.Finally there are latency sources buried elsewhere in the library, including at least 2 needless roundtrips during connection setup. Fighting latency is an endless war, but with module loading working efficiently, the most important battle is over.
-
Mitogen, an infrastructure code baseline that sucks less

After many years of occasional commitment, I'm finally getting close to a solid implementation of a module I've been wishing existed for over a decade: given a remote machine and an SSH connection, just magically make Python code run on that machine, with no hacks involving error-prone shell snippets, temporary files, or hugely restrictive single use request-response shell pipelines, and suchlike.
I'm borrowing some biology terminology and calling it Mitogen, as that's pretty much what the library does. Apply some to your program, and it magically becomes able to recursively split into self-replicating parts, with bidirectional communication and message routing between all the pieces, without any external assistance beyond an SSH client and/or sudo installation.
Mitogen's goal is straightforward: make it childsplay to run Python code on remote machines, eventually regardless of connection method, without being forced to leave the rich and error-resistant joy that is a pure-Python environment. My target users would be applications like Ansible, Salt, Fabric and similar who (through no fault of their own) are universally forced to resort to obscene hacks in their implementations to affect a similar result. Mitogen may also be of interest to would-be authors of pure Python Internet worms, although support for autonomous child contexts is currently (and intentionally) absent.
Because I want this tool to be useful to infrastructure folk, Mitogen does not require free disk space on the remote machines, or even a writeable filesystem -- everything is done entirely in RAM, making it possible to run your infrastructure code against a damaged machine, for example to implement a repair process. Newly spawned Python interpreters have import hooks and logging handlers configured so that everything is fetched or forwarded over the network, and the only disk accesses necessary are those required to start a remote interpreter.
Recursion
Mitogen can be used recursively: newly started child contexts can in turn be used to run portions of itself to start children-of-children, with message routing between all contexts handled automatically. Recursion is used to allow first SSHing to a machine before sudoing to a new account, all with the user's Python code retaining full control of each new context, and executing code in them transparently, as easily as if no SSH or sudo connection were involved at all. The master context is able to control and manipulate children created in this way as easily as if they were directly connected, the API remains the same.
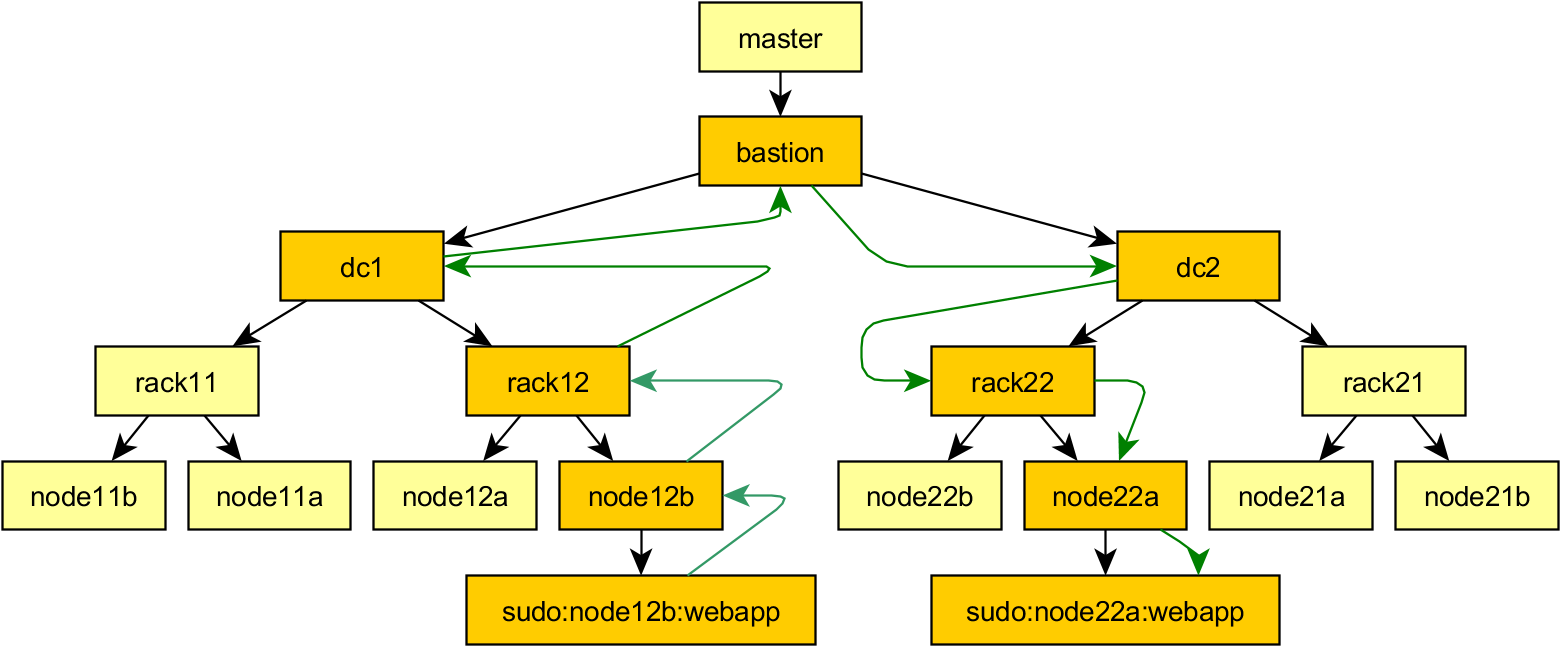
Currently there exists just two connection methods: ssh and sudo, with the sudo support able to cope with typing passwords interactively, and crap configurations that have
requirettyenabled.I am explicitly planning to support Windows, either via WMI, psexec, or Powershell Remoting. As for other more exotic connection methods, I might eventually implement bootstrap over an IPMI serial console connection if for nothing else then as a demonstrator of how far this approach can be taken, but the ability to use the same code to manage a machine with or without a functional networking configuration would be in itself a very powerful feature.
This looks a bit like X. Isn't this just X?
Mitogen is far from the first Python library to support remote bootstrapping, but it may be the first to specifically target infrastructure code, minimal networking footprint, read-only filesystems, stdio and logging redirection, cross-child communication, and recursive operation. Notable similar packages include Pyro and py.execnet.
This looks a bit like Fabric. Isn't this just Fabric?
Fabric's API feels kinda similar to what Mitogen offers, but it fundamentally operates in terms of chunks of shell snippets to implement all its functionality. You can't easily (at least, as far as I know) trick Fabric into running your Python code remotely, or for that matter recursively across subsequent sudo and SSH connections, and arrange for that code to communicate bidirectionally with code running in the local process and autonomously between any spawned children.
Mitogen internally reuses this support for bidirectional communication to implement some pretty exciting functionality:
SSH Client Emulation
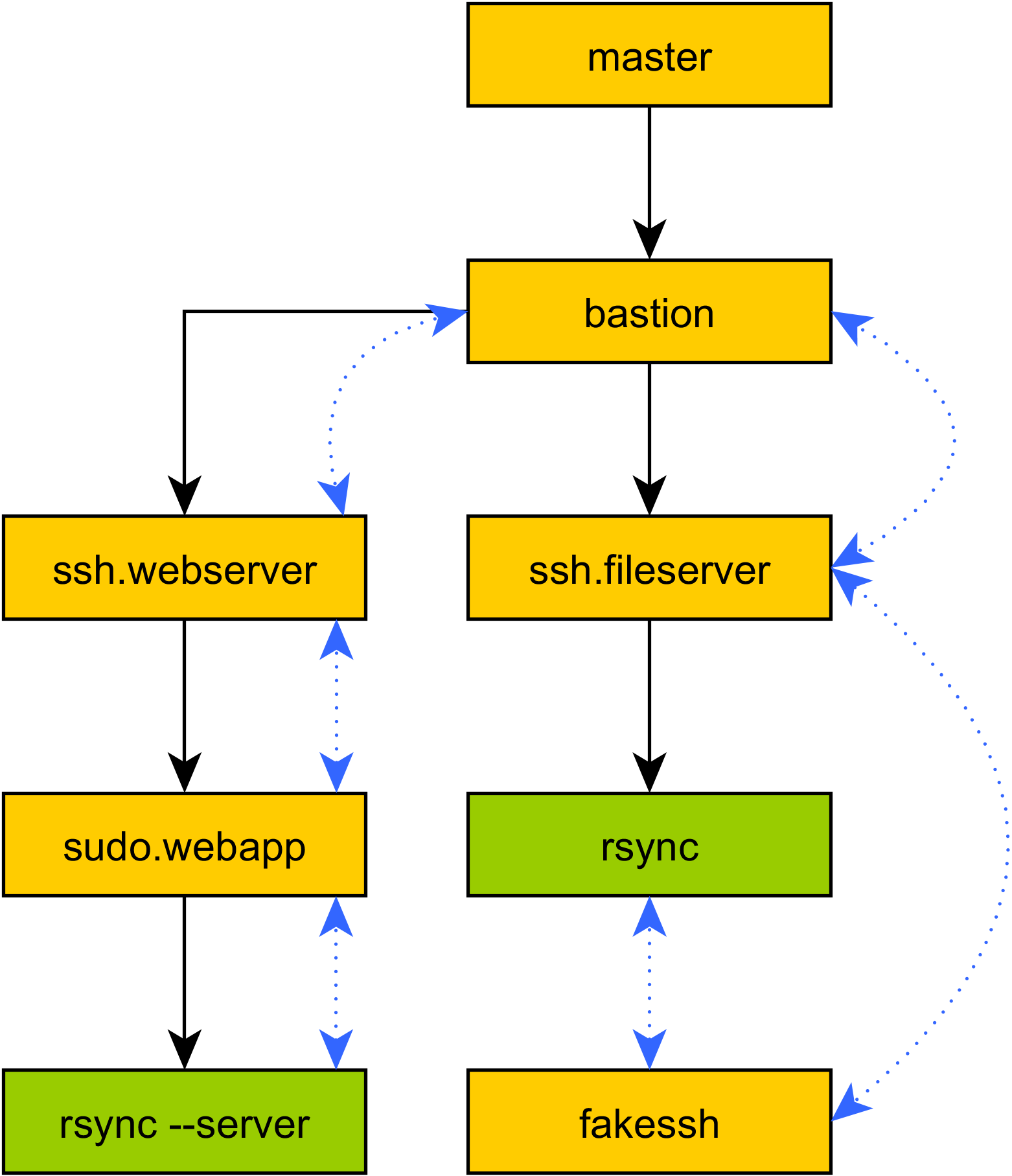 So your program has an elaborate series of tunnels setup, and it's running code all over the place. You hit a problem, and suddenly feel the temptation to drop back to raw shell and SSH again: "I just need to sync some files!", you tell yourself, before loudly groaning on realizing the spaghetti of duplicated tunnel configurations that would be required to get
So your program has an elaborate series of tunnels setup, and it's running code all over the place. You hit a problem, and suddenly feel the temptation to drop back to raw shell and SSH again: "I just need to sync some files!", you tell yourself, before loudly groaning on realizing the spaghetti of duplicated tunnel configurations that would be required to get rsyncrunning the same way as your program. What's more, you realize that you can't even usersync, because you're relying on Mitogen's ability to run code oversudowithrequirettyenabled, and you can't even directly log into that target account.Not a problem: Mitogen supports running local commands with a modified environment that causes their attempt to use SSH to run remote command lines to be redirected into Mitogen, and tunnelled over your program's existing tunnels. No duplicate configuration, no wasted SSH connections, no 3-way handshake latency.
The primary goal of the SSH emulator to simplify porting existing infrastructure scripts away from shell, including those already written in Python. As a first concrete target for Mitogen, I aim to retrofit it to Ansible as a connection plug-in, where this functionality becomes necessary to support e.g. Ansible's
synchronizemodule.Compared To Ansible
To understand the value of Mitogen, a short comparison against Ansible may be useful. I created an Ansible playbook talking to a VMWare Fusion Ubuntu machine, with SSH pipelining enabled (the current best performance mode in Ansible). The playbook simply executes
/bin/truewithbecome: trueand discards the result 100 times.I then created an equivalent script written against Mitogen, using its SSH and sudo functionality, and finally a trivial change to the Mitogen variant that executes the control loop on the target machine. In terms of architecture, the first Mitogen script is closer to a fair comparison to Ansible's control flow, but the latter is a good example of the kind of intelligence Mitogen enables that would be messy, if not close to impossible with Ansible's existing architecture.
[Side note: this is comparing performance characteristics only, in particular I am not advocating writing code against Mitogen directly! It's possible, but you get none of the ease of use that a tool like Ansible provides. On saying that, though, a Mitogen-enabled tool composed of tens of modules would have similar performance to the numbers below, just a slightly increased base cost due to initial module upload]
Method Bytes A→B Bytes B→A Packets A→B Packets B→A Duration (ms) Ansible default 5,001,352 486,500 8,864 4,460 55,065 Ansible pipelining 4,562,905 178,622 4,282 2,033 25,643 Mitogen local loop 45,847 17,982 247 135 1,245 Mitogen remote loop 22,511 5,766 51 39 784 The first and most obvious property of Ansible is that it uses a metric crap-ton of bandwidth, averaging 45kb of data for each run of /bin/true. In comparison, the raw command line "
ssh host /bin/true" generates only 4.7kb and 311ms, including SSH connection setup and teardown.Bandwidth aside, CPU alone cannot account for runtime duration, clearly significant roundtrips are involved, generating sufficient latency to become visible on an in-memory connection to a local VM. Why is that? Things are about to get real ugly, and I'm already starting to feel myself getting depressed. Remember those obscene hacks I mentioned earlier? Well, buckle your seatbelt Dorothy, because Kansas is going bye-bye..
The Ugly
[Side note: the name Ansible is borrowed from Ender's Game, where it refers to a faster-than-light communication technology. Giggles]
 When you write some code in Ansible, like
When you write some code in Ansible, like shell: /bin/true, you are telling Ansible (in most cases) that you want to execute a module namedshell.pyon the target machine, passing/bin/trueas its argument.So far, so logical. But how is Ansible actually running
shell.py? "Simple", by default (no pipelining) it looks like this:- First it scans
shell.pyfor every module dependency, - then it adds the module and all dependents into an in-memory ZIP file, alongside a file containing the module's serialized arguments,
- then it base64-encodes this ZIP file and mixes it into a templatized self-extracting Python script (
module_common.py), - then it writes the templatized script to the local filesystem, where it can be accessed by
sftp, - then it uploads the script to the target machine:
- first it runs a fairly simple bash snippet over SSH to find the user's home directory,
- then it runs a bigger bash snippet to create a temporary directory in the user's home directory in which to write the templatized script,
- then it starts an sftp session and uses it to write the templatized script to the new temporary directory,
- then it runs another snippet over SSH to mark the script executable,
- then it wraps a snippet to execute the templatized script using an obscene layer of quoting (16 quotes!!!) and passes it to sudo,
- finally the templatized script runs:
- first it creates yet another temporary directory on the target machine, this time using the
tempfilemodule, - then it writes a base64-decoded copy of the embedded ZIP file as
ansible_modlib.zipinto that directory, - then it opens the newly written ZIP file using the
zipfilemodule and extracts the module to be executed into the same temporary directory, named likeansible_mod_<modname>.py, - then it opens the newly written ZIP file in append mode and writes a custom
sitecustomize.pymodule into it, causing the ZIP file to be written to disk for a second time on this machine, and a third time in total, - then it uses the
subprocessmodule to execute the extracted script, withPYTHONPATHset to cause Python's ZIP importer to search for additional dependent modules inside the extracted-and-modified ZIP file, - then it uses the
shutilmodule to delete the second temporary directory,
- first it creates yet another temporary directory on the target machine, this time using the
- then the shell snippet that executed the templatized script is used to run
rm -rfover the first temporary directory.
When pipelining is disabled, which is the default, and required for cases where
sudohasrequirettyenabled, these steps (and their associated network roundtrips) recur for every single playbook step. And now you know why Ansible makes execution over a local 1Gbit LAN feel like it's communicating with a host on Mars.Need a breath? Don't worry, things are about to get better. Here are some pretty graphs to look at while you're recovering..
The Ugly (from your network's perspective)
This shows Ansible's pipelining mode, constantly reuploading the same huge data part and awaiting a response for each run. Be sure to note the sequence numbers (transmit byte count) and the scale of the time axis:

Now for Mitogen, demonstrating vastly more conservative use of the network:

The SSH connection setup is clearly visible in this graph, accounting for about the first 300ms on the time axis. Additional excessive roundtrips are visible as Mitogen waits for its command-line to signal successful first stage bootstrap before uploading the main implementation, and 2 subsequent roundtrips first to fetch
mitogen.sudomodule followed by themitogen.mastermodule. Eliminating module import roundtrips like these will probably be an ongoing battle, but there is a clean 80% solution that would apply in this specific case I just haven't gotten around to implementing yet.The fine curve representing repeated executions of
/bin/trueis also visible: each bump in the curve is equivalent to Ansible's huge data uploads from earlier, but since Mitogen caches code in RAM remotely, unlike Ansible it doesn't need to reupload everything for each call, or start a new Python process, or rewrite a ZIP file on disk, or .. etc.Finally one last graph, showing Mitogen with the execution loop moved to the remote machine. All the latency induced by repeatedly invoking
/bin/truefrom the local machine has disappeared.
The Less Ugly
Ansible's pipelining mode is much better, and somewhat resembles Mitogen's own bootstrap process. Here the templatized initial script is fed directly into the target Python interpreter, however they immediately deviate since Ansible starts by extracting the embedded ZIP file per step 8 above, and discarding all the code it uploaded once the playbook step completes, with no effort made to preserve either the Python processes spawned, or the significant amount of uploaded module code for each step.
Pipelining mode is a huge improvement, however it still suffers from making use of the SSH stdio pipeline only once (which was expensive to setup, even with multiplexing enabled), the destination Python interpreter only once (usually ~100ms+ per invocation), and as mentioned repeatedly, no caching of code in the target, not even on disk.
When Mitogen is executing your Python function:
- it executes SSH with a single Python command-line,
- then it waits for that command-line to report
"EC0"on stdout, - then it writes a copy of itself over the SSH pipe,
- meanwhile the remote Python interpreter forks into two processes,
- the first re-execs itself to clear the huge Python command-line passed over SSH, and resets
argv[0]to something descriptive, - the second signals
"EC0"and waits for the parent context to send 7KiB worth of Mitogen source, which it decompresses and feeds to the first before exitting, - the Mitogen source reconfigures the Python module importer, stdio, and logging framework to point back into itself, then starts a private multiplexer thread,
- the main thread writes
"EC1"then sleeps waiting forCALL_FUNCTIONmessages, - meanwhile the multiplexer routes messages between this context's main thread, the parent, and any child contexts, and waits for something to trigger shutdown.
- then it waits for the remote process to report
"EC1", - then it writes a
CALL_FUNCTIONmessage which includes the target module, class, and function name and parameters,- the slave receives the
CALL_FUNCTIONmessage and begins execution, satisfying in-RAM module imports using the connection to the parent context as necessary.
- the slave receives the
On subsequent invocations of your Python function, or other functions from the same module, only steps 3.6, 5, and 5.1 are necessary.
This all sounds fine and dandy, but how can I use it?
I'm working on it! For now my goal is to implement enough functionality so that Mitogen can be made to work with Ansible's process model. The first problem is that Ansible runs playbooks using multiple local processes, and has no subprocess<->host affinity, so it is not immediately possible to cache Mitogen's state for a host. I have a solid plan for solving that, but it's not yet implemented.
There are a huge variety of things I haven't started yet, but will eventually be needed for more complex setups:
-
Getting Started Documentation: it's missing.
-
Asynchronous connect(): so large numbers of contexts can be spawned in reasonable time. For, say, 3 tiers targeting a 1,500 node network connecting in 30 seconds or so: a per-rack tier connecting to 38-42 end nodes, a per-quadrant tier connecting to 10 or so racks, a single box in the datacentre tier for access to a management LAN, reducing latency and caching uploaded modules within a datacenter's network, and the top-level tier which is the master program itself.
-
Better Bootstrap, Module Caching And Prefetching: currently Mitogen is wasting network roundtrips in various places. This makes me lose sleep.
-
General Robustness: no doubt with real-world use, many edge cases, crashes, hangs, races and suchlike will be be discovered. Of those, I'm most concerned with ensuring the master process never hangs with CTRL+C or
SIGTERM, and in the case of master disconnect, orphaned contexts completely shut down 100% of the time, even if their main thread has hung. -
Better Connection Types: it should at least support SSH connection setup over a transparently forwarded TCP connection (e.g. via a bastion host), so that key material never leaves the master machine. Additionally I haven't even started on Windows support yet.
-
Security Audit: currently the package is using cPickle with a highly restrictive class whitelist. I still think it should be possible to use this safely, but I'm not yet satisfied this is true. I'd also like it to optionally use JSON if the target Python version is modern enough. Additionally some design tweaks are needed to ensure a compromised slave cannot use Mitogen to cross-infect neighbouring nodes.
-
Richer Primitives: I've spent so much effort keeping the core of Mitogen compact that overall design has suffered, and while almost anything is possible using the base code, often it involves scrobbling around in the internal plumbing to get things working. Specifically I'd like to make it possible to pass
Contexthandles as RPC parameters, and generalise thefakesshcode so that it can handle other kinds of forwarding (e.g. TCP connections, additional UNIX pipe scenarios). -
Tests. The big one: I've only started to think about tests recently as the design has settled, but so much system-level trickery is employed, always spread out across at least 2 processes, that an effective test strategy is so far elusive. Logical tests don't capture any of the complex OS/IO ordering behaviour, and while typical integration tests would capture that, they are too coarse to rely on for catching new bugs quickly and with strong specificity.
Why are you writing about this now?
If you read this far, there's a good chance you either work in infrastructure tooling, or were so badly burned by your experience there that you moved into management. Either way, you might be the person who could help me spend more time on this project. Perhaps you are on a 10-person team with a budget, where 30% of the man-hours are being wasted on Ansible's connection latency? If so, you should definitely drop me an e-mail.
The problem with projects like this is that it is almost impossible to justify commercially, it is much closer to research than product, and nobody ever wants to pay for that. However, that phase is over, the base implementation looks clean and feels increasingly solid, my development tasks are becoming increasingly target-driven, and I'd love the privilege to polish up what I have, to make contemporary devops tooling a significantly less depressing experience for everyone involved.
If you merely made it to the bottom of the article because you're interested or have related ideas, please drop me an e-mail. It's not quite ready for the prime time, but things work more than sufficiently that early experiementation is probably welcome at this point.
Meanwhile I will continue aiming to make it suitable for use with Ansible, or perhaps a gentle fork of Ansible, since its internal layering isn't the greatest.
- First it scans